
CellShield
Reporting & Maskierung von PII in Microsoft Excel® TabellenVersion: 2
Aktualisiert am 22. Jul 2025 durch JET-Software GmbH
Version: 2
IRI CellShield Enterprise Edition (EE) ist eine innovative Datensicherheitslösung, die speziell entwickelt wurde, um sensible Informationen in Excel-Tabellen zu schützen. In einer Zeit, in der Datenschutzverletzungen immer häufiger vorkommen, bietet CellShield EE Unternehmen, gemeinnützigen Organisationen und Behörden eine effektive Möglichkeit, personenbezogene Daten (PII) in ihren Tabellenkalkulationen zu sichern.
CellShield EE ist das umfassende Datenentdeckungs-, Maskierungs- und Auditierungspaket für Excel, das direkt in der Excel-Umgebung arbeitet. Dies ermöglicht eine nahtlose Integration in bestehende Arbeitsabläufe ohne Unterbrechung der Produktivität.
Ein Finanzdienstleister verwendet CellShield EE, um Kundendaten in Excel-Berichten zu schützen. Vor einer Präsentation für externe Berater nutzt das Unternehmen die automatische Suchfunktion, um alle Tabellenblätter auf sensible Informationen zu prüfen. Die Software identifiziert Kundennamen, Adressen und Kontodaten. Mit wenigen Klicks werden diese Informationen pseudonymisiert, sodass die Daten für Analysezwecke nutzbar bleiben, ohne die Privatsphäre der Kunden zu gefährden. Die automatische Auditierungsfunktion protokolliert alle Änderungen, was dem Unternehmen hilft, seine Datenschutzpraktiken bei Bedarf nachzuweisen.
Durch den Einsatz von CellShield EE kann das Unternehmen vertrauliche Informationen effektiv schützen, gleichzeitig produktiv arbeiten und das Vertrauen seiner Kunden stärken.
Kompatibel mit IRI FieldShield:
Beachten Sie, dass die in CellShield unterstützten reversiblen Funktionen kompatibel sind mit jenen in IRI FieldShield (zur statischen oder dynamischen Absicherung von PII in diversen Datenbank- und Dateiquellen). Dies bedeutet, dass die Informationen, die Sie in einem Tool schützen, mithilfe des anderen Tools in einem anderen System in kollaborativer Weise offengelegt werden können.
Seit 1978 weltweit im B2B-Sektor anerkannt: Bei Großunternehmen, Banken, Versicherungen sowie Behörden im Einsatz!
Schnelle, sichere und kosteneffiziente Datenverarbeitung: Für IT-Experten, die große und sensible Datenmengen effizient verarbeiten wollen!
Seit über 40 Jahren nutzen unsere Kunden weltweit aktiv unsere Software für Big Data Wrangling und Schutz! Dazu gehören NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,..
Sie finden eine Auswahl weltweiter Referenzen hier und eine Auswahl deutscher Referenzen hier:
Das hängt von Ihren Datenquellen, Zielen und bis zu einem gewissen Grad von der Art der benötigten Funktionalität ab. Es sind zusätzlich weitere Funktionen für das Datenbank-Subsetting und die synthetische Testdatengenerierung vorhanden.
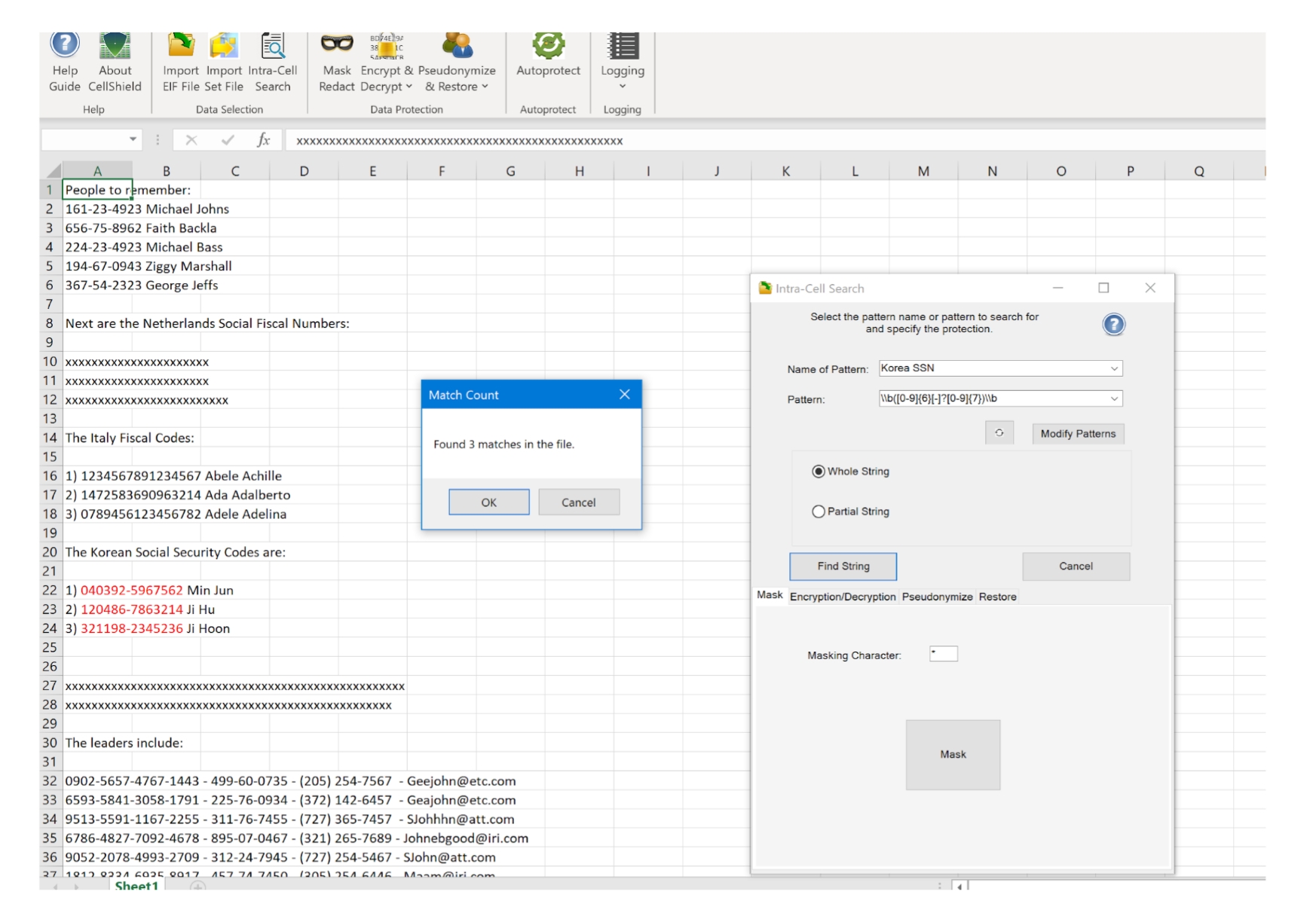
Durch die konsistente Anwendung derselben Maskierungsfunktion auf denselben Klartext, jedes Mal automatisch und global. Dies geschieht durch Regeln, die mit mustergleichen Spaltennamen verknüpft sind, oder, noch zuverlässiger, durch integrierte Datenklassen, die an identifizierte Daten gebunden sind. Klassifizierte Daten werden durch robuste integrierte Wertesuchmethoden wie RegEx-Musterübereinstimmungen mit benutzerdefinierten Genauigkeitsschwellenwerten, Nachschlagewertübereinstimmungen, Fuzzy-Match-Algorithmen, benannte Entitäts- und Gesichtserkennungsmodelle oder JSON/XML/CSV/DB-Pfad-(Spalten-)Filter entdeckt/geprüft. Beachten Sie, dass alle IRI Shield-Produkte - FieldShield, DarkShield und CellShield EE - dieselben Datenklassen und deterministischen Maskierungsfunktionen nutzen, um die Konsistenz und damit die Daten- und Referenzintegrität nach der Maskierung in Ihren strukturierten, halbstrukturierten und unstrukturierten Unternehmensquellen zu gewährleisten.
Die integrierte Datenklassifizierungsfunktionalität von IRI macht außerdem formell definierte Primär- und Fremdschlüssel bei der Erstellung von Datenbankschemata überflüssig. Dies unterstützt die Datenintegrität in relationalen Datenbanken ohne Einschränkungen genauso wie in Dateien, Dokumenten und Bildern.
Die Stellen, an denen Einschränkungen definiert werden müssen, um die referentielle Integrität in künstlich erzeugten RDB-Testdaten automatisch zu unterstützen, befinden sich in den IRI-Assistenten für die DB-Subsetierung und die DB-Testdatensynthese. Wenn diese Einschränkungen nicht definiert sind, ist es zwar immer noch möglich, Testdaten für DBs zu subsetten und zu synthetisieren, aber es sind mehr manuelle Eingriffe erforderlich.
Die Techniken, die Ihren geschäftlichen Anforderungen gerecht werden. In IRI FieldShield (oder dem Programm SortCL in IRI CoSort) können Sie jede dieser Techniken auf einer Feld-/Spaltenbasis anwenden:
Die Entscheidungskriterien dafür, welche Schutzfunktion für die einzelnen Daten zu verwenden ist, sind:
Beachten Sie auch, dass Sie ein oder mehrere Felder mit denselben oder unterschiedlichen Funktionen schützen können oder einen oder mehrere Datensätze ganz schützen können („wholerec“). In jedem Fall können die Bedingungskriterien und die Ziel-/Layout-Parameter ebenfalls angepasst und mit der Datenumwandlung und der Berichterstellung im selben Auftrag kombiniert werden. Und in zweckmäßigen Assistenten für mehrere Tabellen oder durch globale Datenklassifizierung können DBAs und Datenverwalter diese Schutzmaßnahmen als Regeln anwenden, um Konsistenz und referenzielle Integrität datenbank- oder unternehmensweit zu wahren.
Beides, wobei das Maskieren von Quelle zu Ziel häufiger genutzt wird. Für In-Place-Masking kann einfach die Quelle als Ziel angegeben werden.
Wir empfehlen, dies erst nach einer erfolgreichen Überprüfung des Outputs (z. B. anhand einer kleinen Testdatei oder stdout) durchzuführen, um sicherzustellen, dass das Ergebnis den gewünschten Anforderungen in Bezug auf Format, Darstellung und Funktionalität (z. B. Reversibilität durch Entschlüsselung) entspricht – insbesondere, wenn keine Sicherungskopie vorhanden ist.
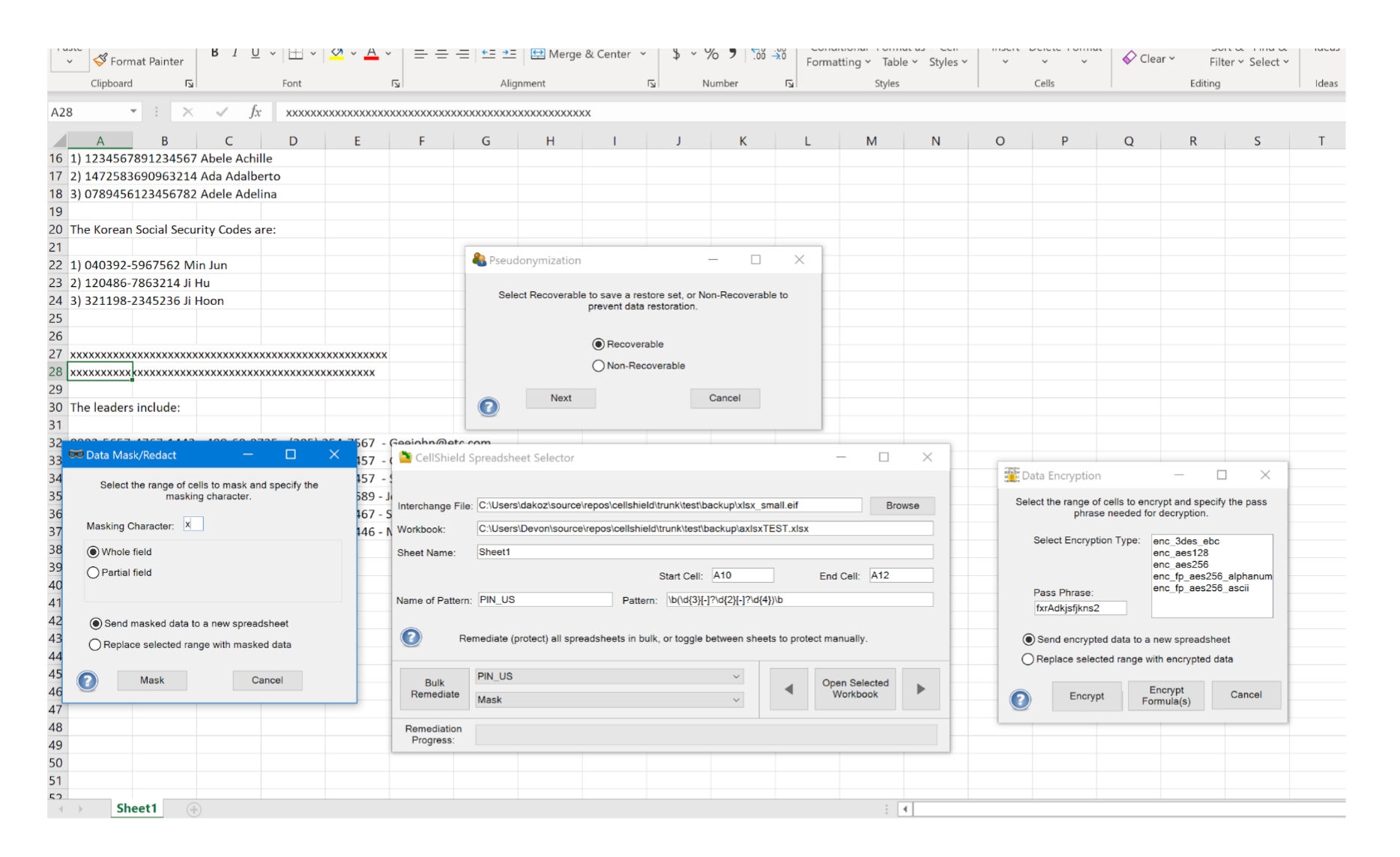
In den IRI-Datenmaskierungsprodukten wie FieldShield, CellShield und DarkShield bedeutet Pseudonymisierung das Ersetzen (Substituieren) einer Identität durch eine andere. Je nach Anwendungsfall können diese Werte konsistent und reproduzierbar sein, einige davon reversibel oder wiederherstellbar, während andere zufällig bleiben.
Alle IRI-Pseudonymisierungstechniken basieren auf der Nutzung einer Ersatzwert-Datei. Falls die Ersatzwerte konsistent sein sollen, muss diese Datei zwei durch ein Tabulatorzeichen getrennte Spalten enthalten. Diese sogenannten Lookup-Set-Dateien (Crosswalks) gewährleisten eine eindeutige Zuordnung zwischen Original- und Ersatzwerten.
Die Anforderungen an eine Lookup-Set-Datei sind einfach:
In einigen Fällen kann die Anwendung die Set-Dateien basierend auf den vorhandenen Daten und einer optionalen Liste möglicher Ersatzwerte automatisch erstellen. Dies ist jedoch nicht möglich, wenn die Pseudonymisierung über eine generische Regel angewendet wird. Lookup-Sets für konsistente Ersetzungen können nur direkt über den Feldeinstellungen-Editor erstellt werden, wenn eine einzelne Maskierungsaufgabe erstellt oder bearbeitet wird.
Sind die eindeutigen Werte des Quelldatensatzes bekannt, gibt es zwei Möglichkeiten, die Ersatzwerte bereitzustellen:
Bei kleinen Datensätzen ist es oft sinnvoller, eine separate Datei mit Ersatzwerten bereitzustellen. Für große Datensätze kann es hingegen ausreichend sein, eine zufällig gemischte Version der Originalwerte als Ersatz zu verwenden – besonders bei großen Mengen von Werten wie Namen, Straßen oder Städten.
Da die Anzahl möglicher Werte begrenzt ist, spielt es nicht zwingend eine Rolle, ob die Ersatznamen aus einer separaten Liste oder aus den Originaldaten durch Shuffling stammen. Beispielsweise werden in beiden Fällen gängige Vornamen wie „Peter“ oder „Paul“ in den Ersatzwerten enthalten sein.
Die Pseudonymisierung kann sowohl als Regel für eine gesamte Datenklasse als auch individuell pro Feld definiert werden. Die feldspezifischen Einstellungen lassen sich über den Feldeigenschaften-Editor oder das Kontextmenü eines Feldes im Skript-Editor anpassen.
Ja, gleichzeitig. Tatsächlich kann das IRI CoSort-Produkt (über das SortCL-Programm) oder die IRI Voracity (Big Data) Management-Plattform (über SortCL oder austauschbare Hadoop-Engines) auf Feldebene Sicherheit durchsetzen, während Datenintegrations-, Datenqualitäts- und Reporting-Aufgaben ausgeführt werden. Mit anderen Worten, Sie können im gleichen Produkt, Programm und I/O-Durchgang: maskieren/redigieren, verschlüsseln, pseudonymisieren oder anderweitig PII-Werte (personenbezogene Daten) anonymisieren, während Sie die Daten aus heterogenen Datenquellen transformieren, bereinigen und anderweitig neu zuordnen und umformatieren.
Legacy-ETL- und BI-Tools können dies nicht so effizient oder kostengünstig tun. Tatsächlich können Sie in Voracity – das Datenentdeckung, Integration, Migration, Governance und Analyse unterstützt und konsolidiert – Daten gleichzeitig verarbeiten (integrieren, bereinigen usw.), schützen (maskieren) und präsentieren (berichten/analyzieren) oder vorbereiten (mischen/umwandeln/verarbeiten).
Alternativ können Sie IRI-Datenmaskierungsprogramme auf statischen Datenquellen ausführen (oder unsere API-Funktionen dynamisch aufrufen), um nur bestimmte Felder zu schützen, die Ihre bestehende Plattform dann transformieren oder visualisieren wird. Auf diese Weise können Sie:
Es hängt von der Version von Excel ab, die ausgeführt wird (nicht von Ihrem Betriebssystem).
Die CellShield COM-Add-ins für Excel müssen mit der Version von Excel übereinstimmen, die Sie haben. Die Schritte, um die Version von Microsoft Office zu überprüfen, die Sie verwenden, sind wie folgt:
HINWEIS: Sie verwenden möglicherweise nicht unbedingt eine 64-Bit-Version von Microsoft Office, auch wenn Sie eine 64-Bit-Version von Windows XP, Vista oder Windows 7-11 verwenden.
Vom CellShield-Plugin werden keine Daten übertragen. Und weder CellShield noch ein anderes IRI-Produkt zur Erkennung von PII oder zur Maskierung statischer Daten stellt eine Verbindung her oder benötigt diese.
FieldShield, CellShield und DarkShield (sowie CoSort) und damit Voracity werden mit mehreren 128- und 256-Bit-Verschlüsselungsbibliotheken ausgeliefert, die bewährte, konforme 3DES-, AES-, GPG- und OpenSSL-Algorithmen verwenden. Für jedes PII-Element oder jeden Teilstring können Sie die gleiche oder eine andere integrierte Verschlüsselungsroutine verwenden oder eine Verknüpfung zu Ihrer eigenen Verschlüsselungsbibliothek herstellen und diese als benutzerdefinierte Transformationsfunktion auf Feldebene in einem Jobskript angeben. Sie können auch denselben Algorithmus bzw. dieselben Algorithmen und einen anderen Verschlüsselungsschlüssel für jedes Feld verwenden.
Die Verwaltung von Verschlüsselungsschlüsseln wird durch Passphrasen in Jobskripten, sicheren Dateien und Umgebungsvariablen sowie in Drittanbieter-Tresoren wie Azure Key Vault und Townsend Alliance Key Manager unterstützt.
{kind=link}
{kind=link}
{kind=link}