

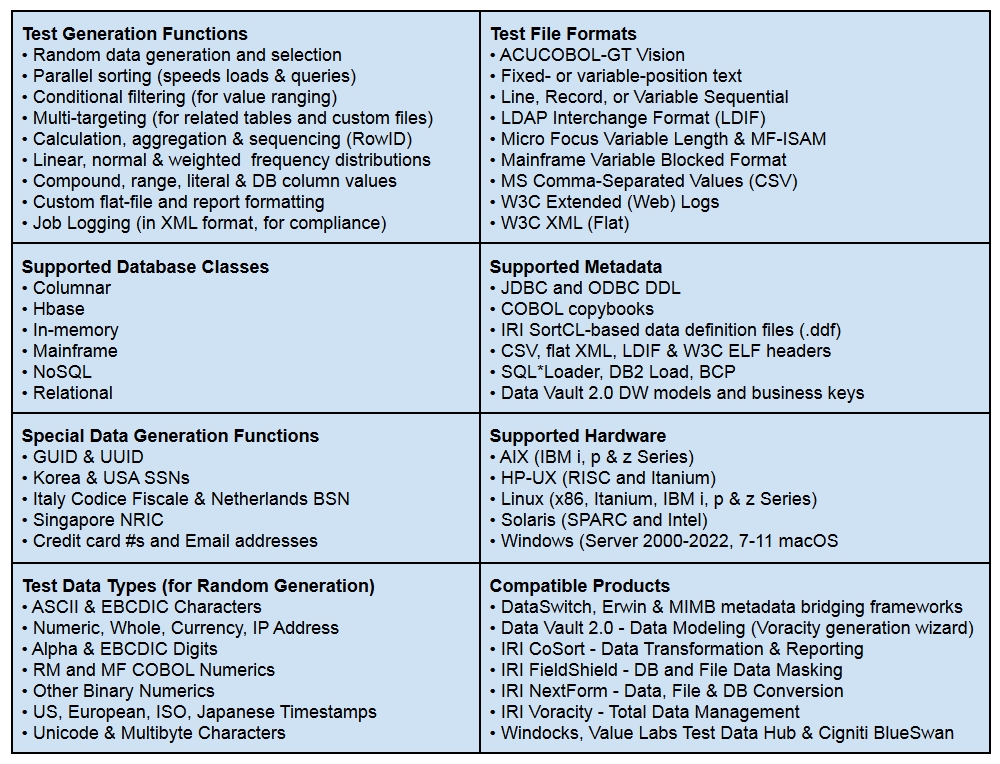
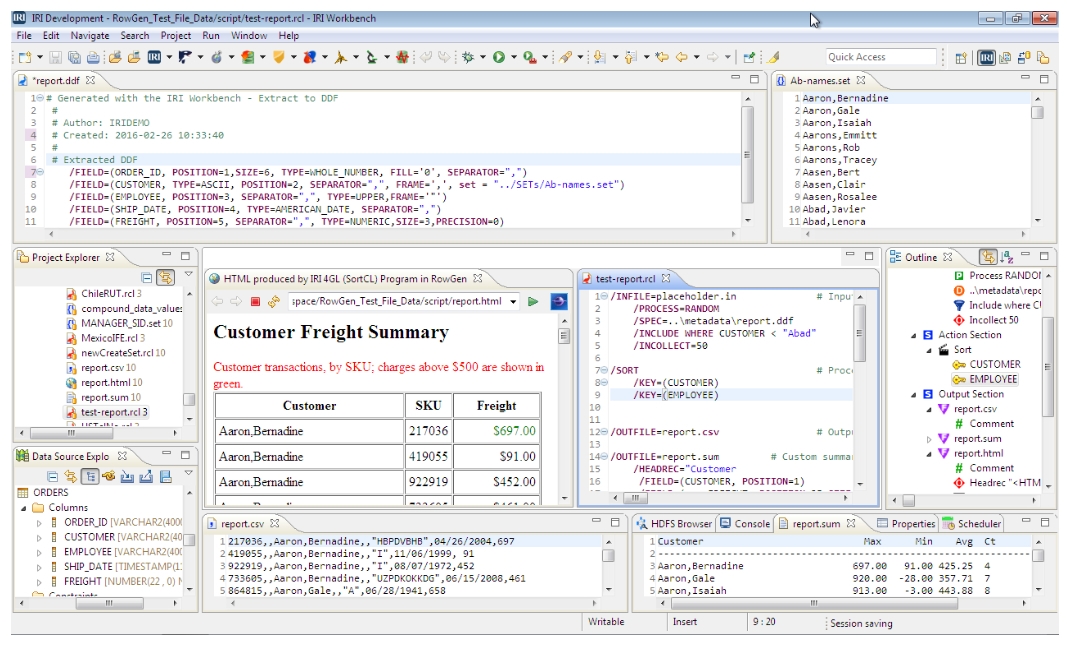
RowGen
Sichere, realistische und referenziell korrekte TestdatenVersion: 4
Aktualisiert am 21. Feb 2025 durch JET-Software GmbH
Version: 4
IRI RowGen ist eine leistungsstarke Softwarelösung, die das zentrale Problem der Testdatengenerierung für Unternehmen löst. Es ermöglicht die schnelle und sichere Erstellung großer Mengen realistischer Testdaten, ohne auf sensible Produktionsdaten zurückgreifen zu müssen.
RowGens herausragendes Merkmal ist die Kombination aus Geschwindigkeit, Datenschutzkonformität und Realitätsnähe der generierten Testdaten. Dank der IRI CoSort Engine bietet RowGen die schnellste Erstellung, Transformation und Massenbewegung großer Testdaten auf dem Markt.
Reduzierung von Datenschutzrisiken durch Vermeidung der Nutzung realer Produktionsdaten
Zeitersparnis bei der Erstellung von Testdatensätzen
Verbesserung der Softwarequalität durch umfassende und realistische Testszenarien
Kosteneffizienz durch Automatisierung der Testdatengenerierung
Ein Finanzdienstleister nutzt RowGen, um eine Testumgebung für sein neues Kundenmanagement-System aufzubauen. Statt sensible Kundendaten zu verwenden, generiert RowGen innerhalb weniger Minuten Millionen von synthetischen Kundendatensätzen, die in Struktur und Verteilung den realen Daten entsprechen. Diese Testdaten ermöglichen es dem Entwicklungsteam, umfangreiche Leistungs- und Funktionstests durchzuführen, ohne Datenschutzbestimmungen zu verletzen. Gleichzeitig können sie verschiedene Szenarien simulieren, indem sie Datenverteilungen und -volumina anpassen, um die Robustheit des Systems unter verschiedenen Bedingungen zu testen.
Seit 1978 weltweit im B2B-Sektor anerkannt: Bei Großunternehmen, Banken, Versicherungen sowie Behörden im Einsatz!
Schnelle, sichere und kosteneffiziente Datenverarbeitung: Für IT-Experten, die große und sensible Datenmengen effizient verarbeiten wollen!
Seit über 40 Jahren nutzen unsere Kunden weltweit aktiv unsere Software für Big Data Wrangling und Schutz! Dazu gehören NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,..
Sie finden eine Auswahl weltweiter Referenzen hier und eine Auswahl deutscher Referenzen hier:
Dies variiert je nach Anwendungsfall, aber soweit RDB-Quellen oder -Ziele involviert sind, werden DBA-Kenntnisse während der Einführung bevorzugt, zusammen mit Wissen über Datenstrukturen und -quellen.
CDO/CISO oder Data Governance/Sicherheitsinteressenvertreter sollten auch an der Definition (Klassifizierung) der sensiblen Datentypen und der auf die Datenklassen anzuwendenden Maskierungsfunktionen (Regeln) beteiligt sein.
Datenwissenschaftler wären hilfreich bei ML/AI-Aspekten im Zusammenhang mit dem Einsatz des DarkShield NER-Modells. BI-/Analytik-Architekten, die mit bestehenden Visualisierungsplattformen vertraut sind, sind hilfreich, um anonymisierte Ausgabedaten, PII-Suchberichte und Betriebsprotokolle für Erkenntnisse und Maßnahmen zu nutzen.
Vertrautheit mit Eclipse, Git, 4GL/3GL (für die API-Nutzung) sowie relevanten Cloud-Verbindungen wäre auch für Produktionsanwender ein gutes Know-how.
TDM-Architekten können auch bei der Definition/Konfiguration sowie bei der Bereitstellung von maskierten, subsettierten oder synthetisierten Daten von Nutzen sein.
Durch die konsistente Anwendung derselben Maskierungsfunktion auf denselben Klartext, jedes Mal automatisch und global. Dies geschieht durch Regeln, die mit mustergleichen Spaltennamen verknüpft sind, oder, noch zuverlässiger, durch integrierte Datenklassen, die an identifizierte Daten gebunden sind. Klassifizierte Daten werden durch robuste integrierte Wertesuchmethoden wie RegEx-Musterübereinstimmungen mit benutzerdefinierten Genauigkeitsschwellenwerten, Nachschlagewertübereinstimmungen, Fuzzy-Match-Algorithmen, benannte Entitäts- und Gesichtserkennungsmodelle oder JSON/XML/CSV/DB-Pfad-(Spalten-)Filter entdeckt/geprüft. Beachten Sie, dass alle IRI Shield-Produkte - FieldShield, DarkShield und CellShield EE - dieselben Datenklassen und deterministischen Maskierungsfunktionen nutzen, um die Konsistenz und damit die Daten- und Referenzintegrität nach der Maskierung in Ihren strukturierten, halbstrukturierten und unstrukturierten Unternehmensquellen zu gewährleisten.
Die integrierte Datenklassifizierungsfunktionalität von IRI macht außerdem formell definierte Primär- und Fremdschlüssel bei der Erstellung von Datenbankschemata überflüssig. Dies unterstützt die Datenintegrität in relationalen Datenbanken ohne Einschränkungen genauso wie in Dateien, Dokumenten und Bildern.
Die Stellen, an denen Einschränkungen definiert werden müssen, um die referentielle Integrität in künstlich erzeugten RDB-Testdaten automatisch zu unterstützen, befinden sich in den IRI-Assistenten für die DB-Subsetierung und die DB-Testdatensynthese. Wenn diese Einschränkungen nicht definiert sind, ist es zwar immer noch möglich, Testdaten für DBs zu subsetten und zu synthetisieren, aber es sind mehr manuelle Eingriffe erforderlich.
Nachdem Sie personenbezogene Daten (PII) in der kostenlosen IRI Workbench IDE (auf Eclipse basierend) für FieldShield, Voracity usw. gefunden und klassifiziert haben, können Sie mit FieldShield oder anderen SortCL-kompatiblen Jobs spezifische Schutzfunktionen auf Feldebene festlegen – entweder ad hoc oder regelbasiert.
Diese statischen Datenmaskierungsfunktionen ermöglichen geschützte Ansichten sensibler Daten (z. B. Sozialversicherungs- oder Telefonnummern, Gehälter, medizinische Codes) in ODBC-verbundenen Datenbanktabellen und sequenziellen Dateien. Dafür stehen 14 verschiedene Techniken zur Verfügung, darunter:
Durch die konsistente Anwendung dieser Methoden (z. B. basierend auf Datenklassen oder musterbasierten Spaltenregeln) bleibt die referenzielle Integrität erhalten.
Weitere Möglichkeiten zur Datenmaskierung und Wahrung der referenziellen Integrität in Voracity sind:
Weitere Informationen finden Sie unter den hier angegebenen Links.
Wie sieht es mit dem Zugriff auf Aktivitätsprotokolldaten für Audits und Berichte aus?
Ja. Im Kontext von IRI Voracity, CoSort, FACT, NextForm oder IRI FieldShield und RowGen können Daten und Metadaten über Rollen getrennt werden:
Durch Zugriffskontrollen auf Client-Computern oder ActiveDirectory/LDAP und Berechtigungen auf Dateiebene. Darüber hinaus kann entweder die erwin (AnalytiX DS)-Governance-Plattform oder ein beliebiges Eclipse-kompatibles SCCS wie Git für Metadaten-Assets - bei dem Berechtigungen nach Rollen konfigurierbar sind - bestimmte Projekte, Jobs und andere Metadaten-Assets sperren.
Ja, mehrere Rollen/Berechtigungen für IRI FieldShield oder Voracity (usw.) Metadaten-Assets (ddf, Job-Skripte, Flows) usw. können durch Systemadministratoren zugewiesen werden, die diesen Assets richtliniengesteuerte ActiveDirectory- oder LDAP-Objekte zuweisen. Weitere Optionen sind die erwin Data Governance Platform (Premium-Option) oder Eclipse Code Control Hubs wie Git; ein Beispiel finden Sie hier.
Der IRI Test Data Hub innerhalb des ValueLabs TDM-Portals unterstützt auch die Zuweisung und Löschung von Administrator- und Testerrollen. Der Administrator der höchsten Ebene kann auch Genehmigungsrechte für Sicherheitsrichtlinien an andere Administratoren delegieren. Solche Rollenberechtigungen werden auf sehr detaillierten Einzel- oder Gruppenebenen festgelegt, die die DB-Anmeldung, die Ausführungsberechtigung, den Datenzugriff und die Berechtigungen zur Abfrage/Berichterstattung/Wiederherstellung des Audit-Protokolls steuern.
Ja, im Kontext von IRI Voracity (für Profiling, ETL, DQ, MDM, BI, etc. ), CoSort (für Datentransformation), FieldShield (für PII-Erkennung und -Maskierung), NextForm (für Datenmigration, Remapping und Replikation) und RowGen (für TDM und Subsetting) kann der Zugriff auf bestimmte Datenquellen (und Ziele, bis hinunter zur Spaltenebene) durch vom DBA erteilte Berechtigungen oder Berechtigungen auf Dateiebene (verwaltet in DSN-Dateien und der IRI Workbench-Datenverbindungsregistrierung) sowie durch Offenbarungsberechtigungen auf Feldebene, die in (sicherbaren) Jobskripten und Entschlüsselungsschlüsseln gesteuert werden, kontrolliert werden.
Im Zusammenhang mit der optionalen proxy-basierten DDM SQL#-Anwendung für FieldShield können Einzel- und Gruppenrollen mit granular definierten Sicherheitsrichtlinien abgeglichen werden, die das Recht bestimmen, sich mit bestimmten DB-Instanzen zu verbinden, bestimmte SQL-Anweisungen auszuführen, Spalten dynamisch zu maskieren (oder nicht), usw.
Beides, da der Zugriff auf Daten, Metadaten und/oder Jobskripte - sowie die Ausführungserlaubnis - mit objektdefinierten ActiveDirectory-, DBA-Login- und/oder Dateisystem-Kontrollen verbunden ist, die auf einer Richtlinienbasis zu Authentifizierungszwecken auferlegt werden.
IRI bietet auch eine optionale proxy-basierte dynamische Datenmaskierung, die abgefragte Spaltenwerte gemäß spezifischer Richtlinien, die einzelne Benutzer, Benutzerrollen oder Benutzergruppen betreffen, unkenntlich machen kann.
Die aufrufenden Anwendungen können auch zusätzliche Ebenen der Benutzerauthentifizierung einführen, um optional eine Lücke zu schließen oder zusätzliche Datenkontaktpunkte zu schützen.
Wir verstehen das und beschleunigen schon seit Jahren Aufträge in älteren ETL-Tools (insbesondere Informatica- und DataStage-Transformationen). Um ETL- und BI-/Analyse-Tools von Drittanbietern sowie DB-Operationen zu beschleunigen, können Sie die skriptfähige(n), stapelverarbeitbare(n) Transformations-Engine(s) von IRI zusammen mit diesen Plattformen einsetzen - und so die Rendite Ihrer Investitionen in diese Plattformen steigern:
ETL-Werkzeuge:
BI-Werkzeuge:
Analytische Werkzeuge:
Datenbanken:
Führen Sie „SortCL“-Programmjobs im IRI CoSort-Paket oder in der IRI Voracity-Plattform über die Kommandozeilenoption (Shell) Ihres Tools aus, um Big Data schneller vorzubereiten und die DB-Tabellen oder Dateiformate aufzufüllen, die Ihr Tool direkt einlesen kann.
Nutzen Sie die gleichen hochleistungsfähigen Datenverarbeitungs-Engines, die auch Voracity nutzen kann: IRI FACT für die Extraktion, IRI CoSort (oder Hadoop) für die Datentransformation, IRI NextForm für die Daten/DB-Migration und Replikation, IRI FieldShield für die Datenmaskierung und/oder IRI RowGen für die Erzeugung von Testdaten.
{kind=link}
{kind=link}
{kind=link}